Training LLMs to Discover Abstractions for
Solving Reasoning Problems
ICLR 2026 · Spotlight, ES-FoMo Workshop @ ICML 2025
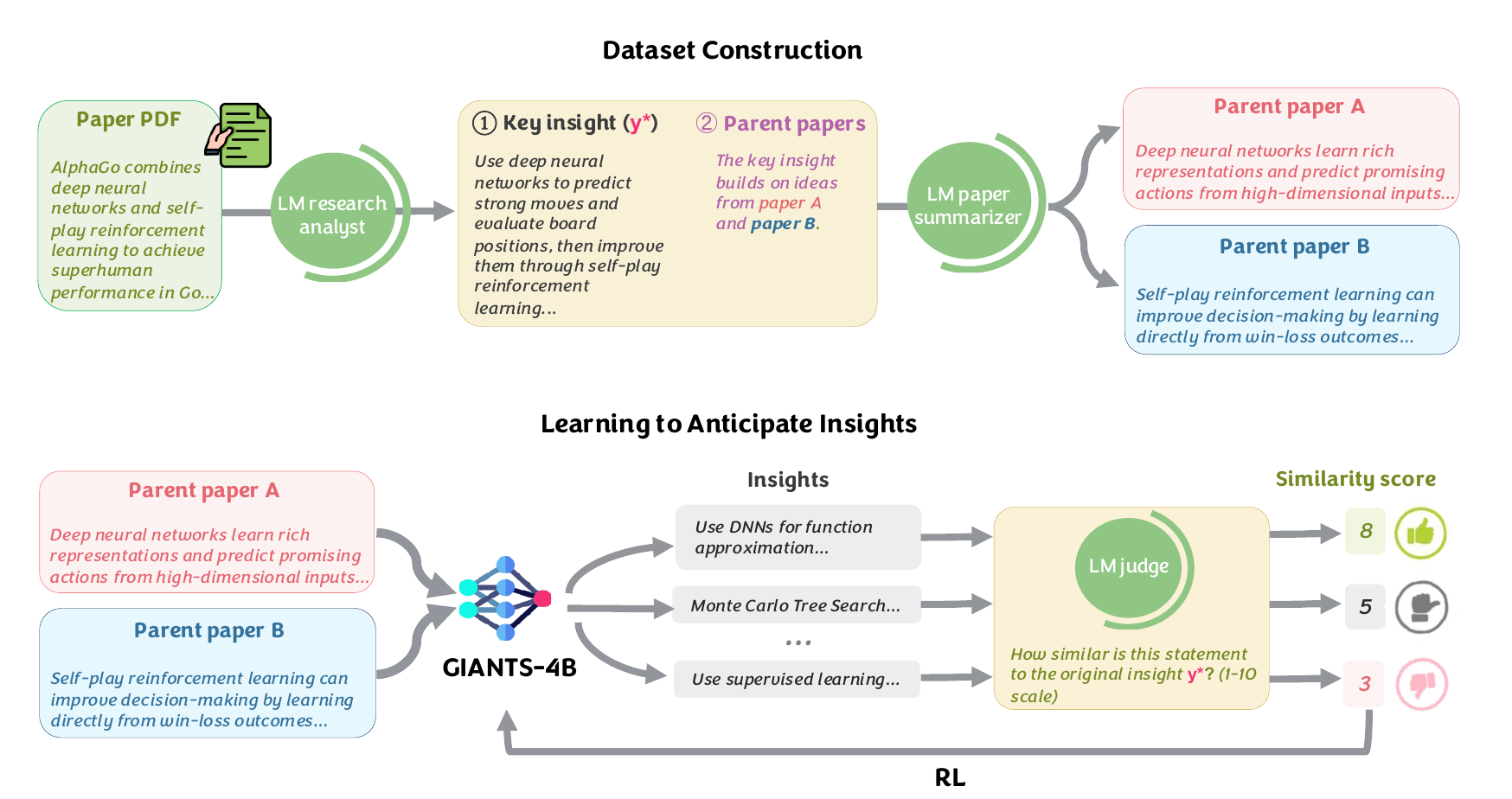
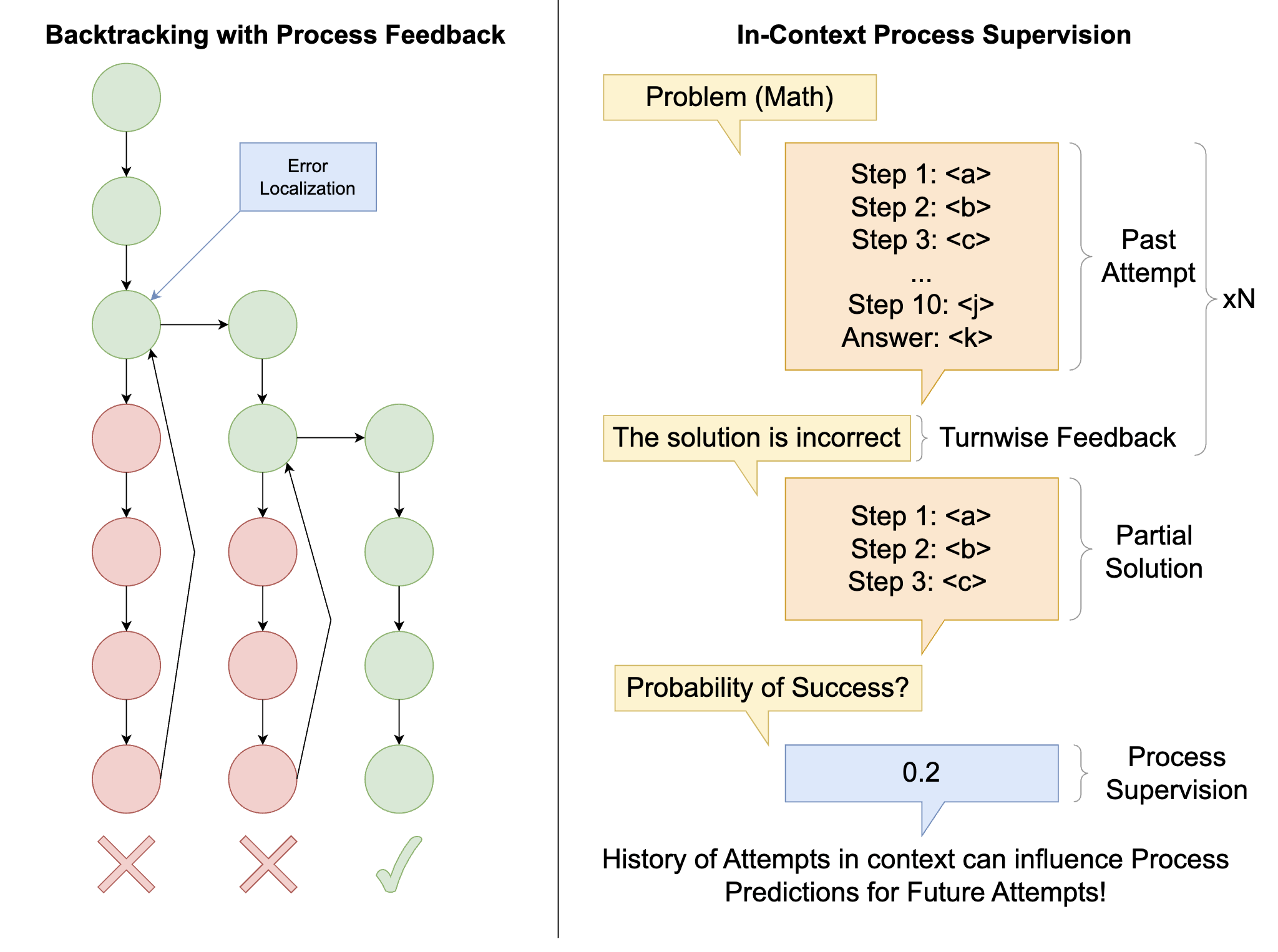
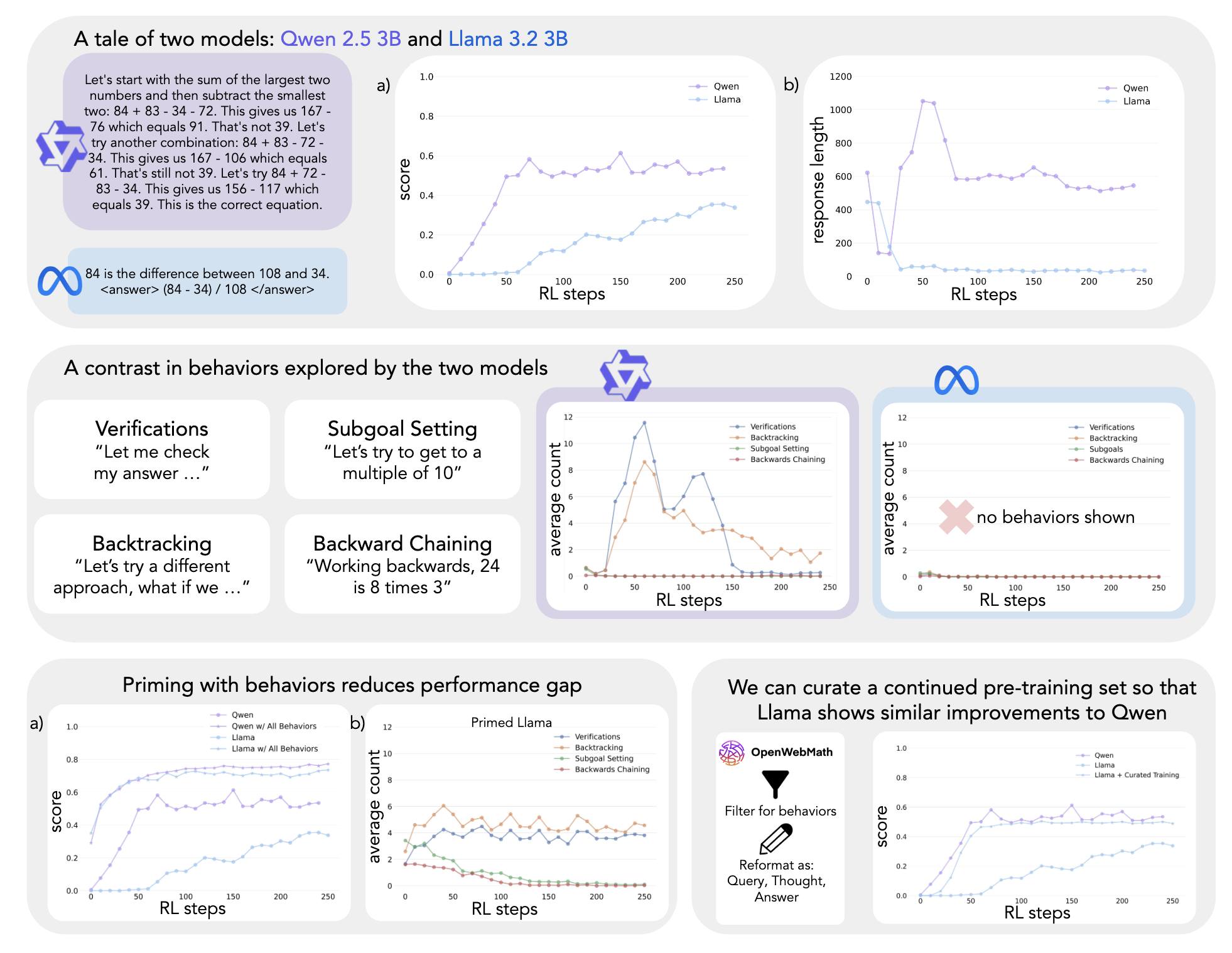
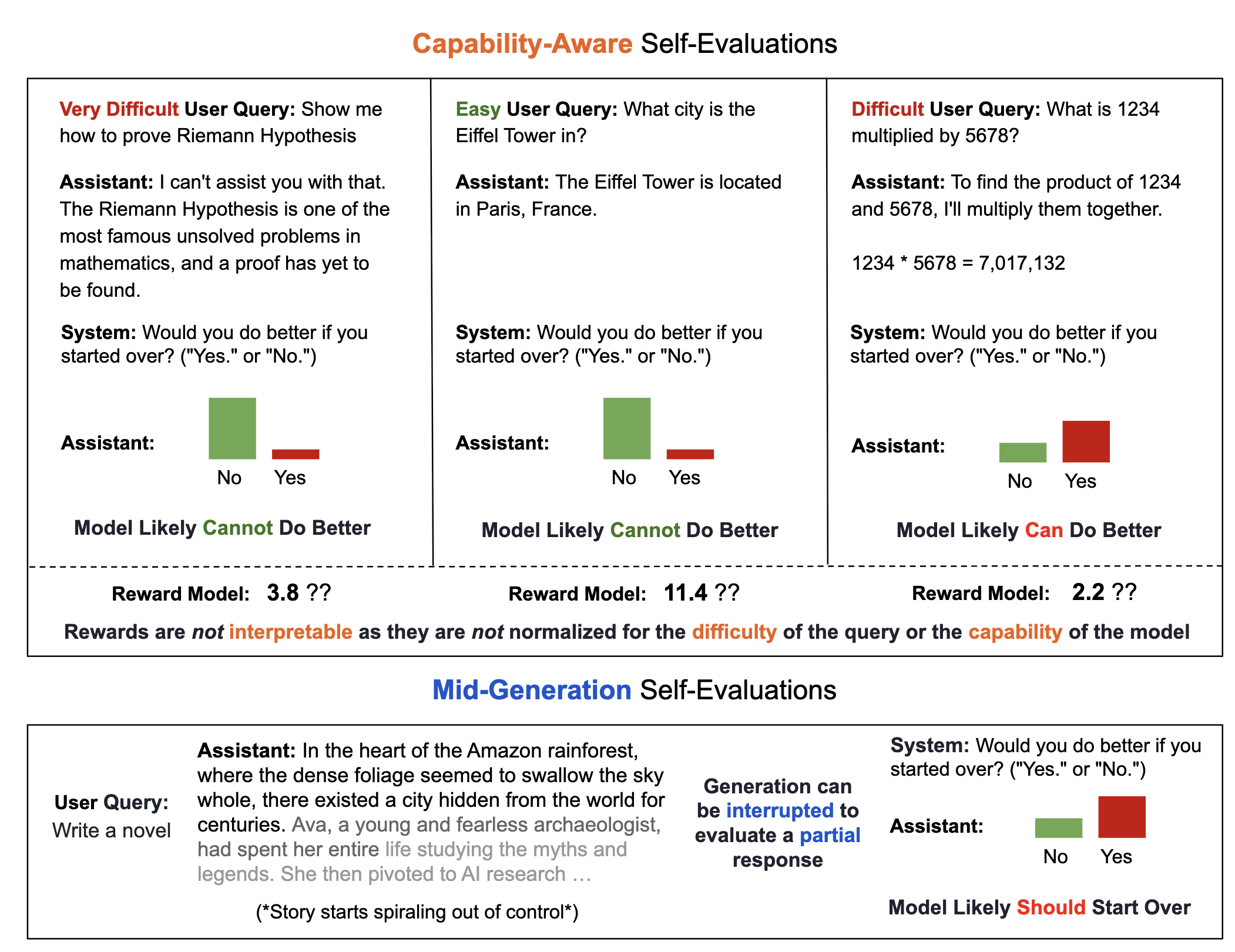
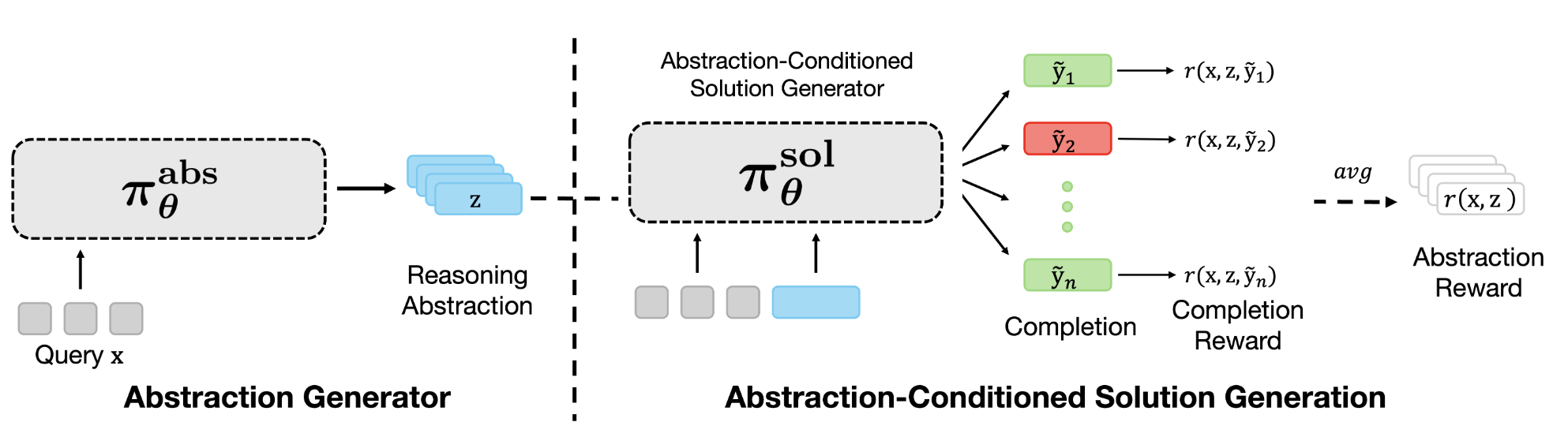
A multi-agent RL method (RLAD) that trains LLMs to discover reusable reasoning abstractions, steering exploration toward useful strategies on hard problems.