|
Anikait Singh I'm a third year Ph.D Student at Stanford AI advised by Chelsea Finn and Aviral Kumar. Previously, I was at UC Berkeley advised by Sergey Levine. I was a research scientist intern at Microsoft Research NYC, Google DeepMind Robotics and Toyota Research Institute. My research is supported by the NSF Graduate Research Fellowship. Email / CV / Scholar / Twitter / Github / Goodreads / Anonymous Feedback |

|
ResearchMy research aims to understand and tackle the core bottlenecks in scaling reinforcement learning to foundation models. I investigate this through the intersection of data and algorithms in two key questions: (1) How can we design simple, scalable, and predictable learning objectives for RL fine-tuning? and (2) Can we systematically curate data distributions to teach models dynamic, adaptive behaviors that supervised methods alone cannot? I explore these questions across a range of domains, from reasoning in mathematics and coding to enabling interaction in robotics and agent-based systems, and developing personalized, preference-aligned models. 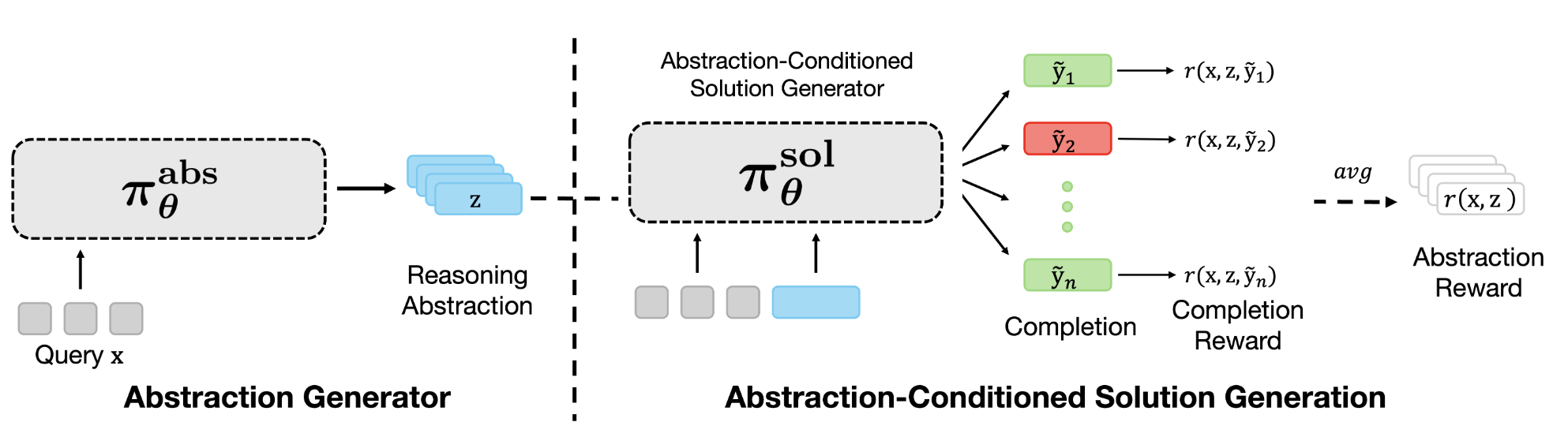
Training LLMs to Discover Abstractions for Solving Reasoning Problems
This paper presents RL for Abstraction Discovery (RLAD), a multi-agent RL method for LLMs to discovers novel "reasoning abstractions" to guide problem solving. This approach can improve the diversity of reasoning strategies explored and steer solution-generators towards useful parts of the solution space for harder problem settings where exploration is required. 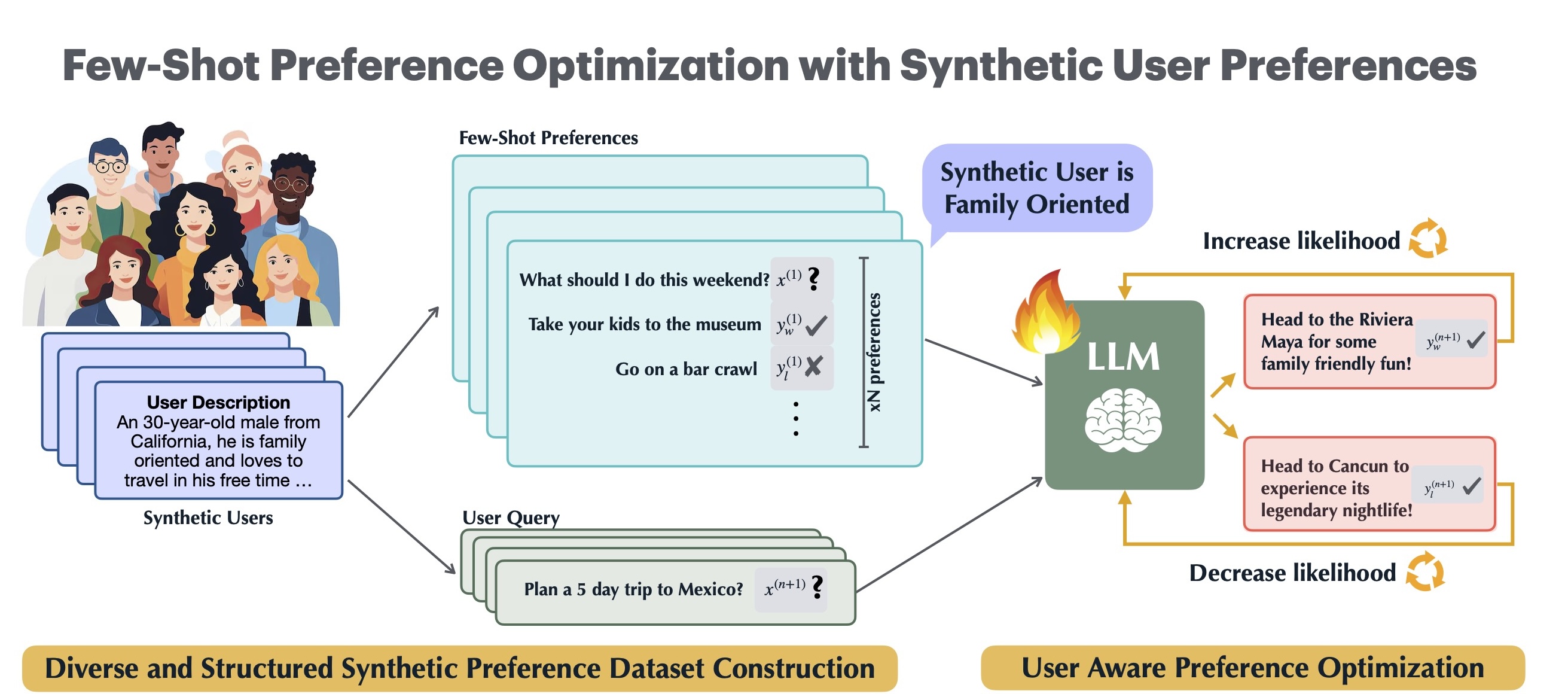
Few-Shot Preference Optimization of Synthetic Preferences Elicits Effective Personalization to Real Users
As language models increasingly interact with a diverse user base, it becomes important for models to generate responses that align with individual user preferences. Few-Shot Preference Optimization (FSPO) is a meta-learning framework that leverages the strong in-context learning capabilities of an LLM to capture the diversity of human preferences. 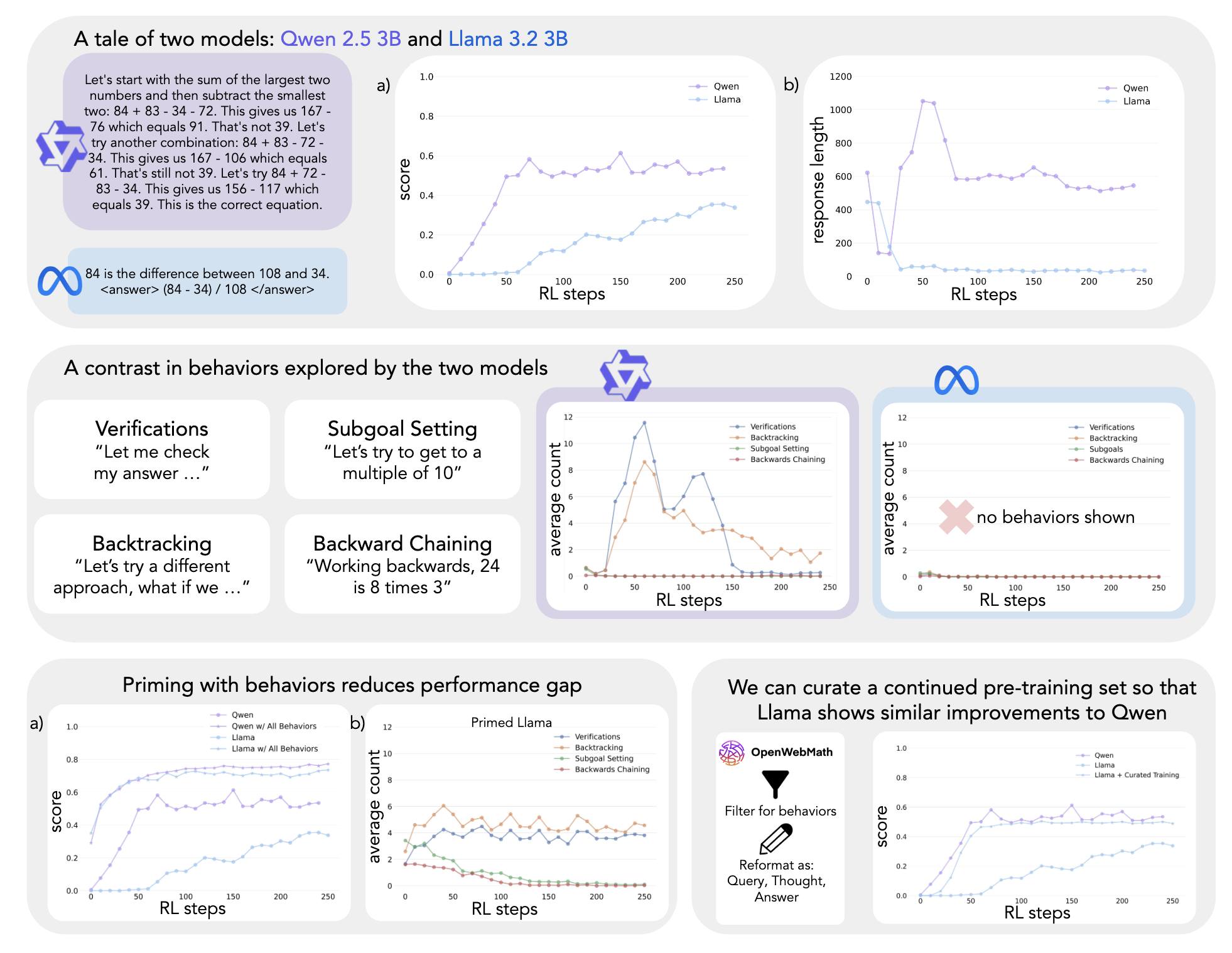
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
This study demonstrates that a language model's intrinsic reasoning behaviors—such as verification, backtracking, subgoal setting, and backward chaining—are key to its ability to self-improve under reinforcement learning. 
MLE-Smith: Scaling MLE Tasks with Automated Multi-Agent Pipeline
This paper introduces MLE-Smith, a fully automated multi-agent generate–verify–execute pipeline that converts raw datasets into competition-style MLE tasks by combining structured task generation (Brainstormer/Designer/Refactor), hybrid verification (deterministic checks + agent review), and execution-based validation to ensure structural integrity, semantic soundness, and empirical solvability at scale.
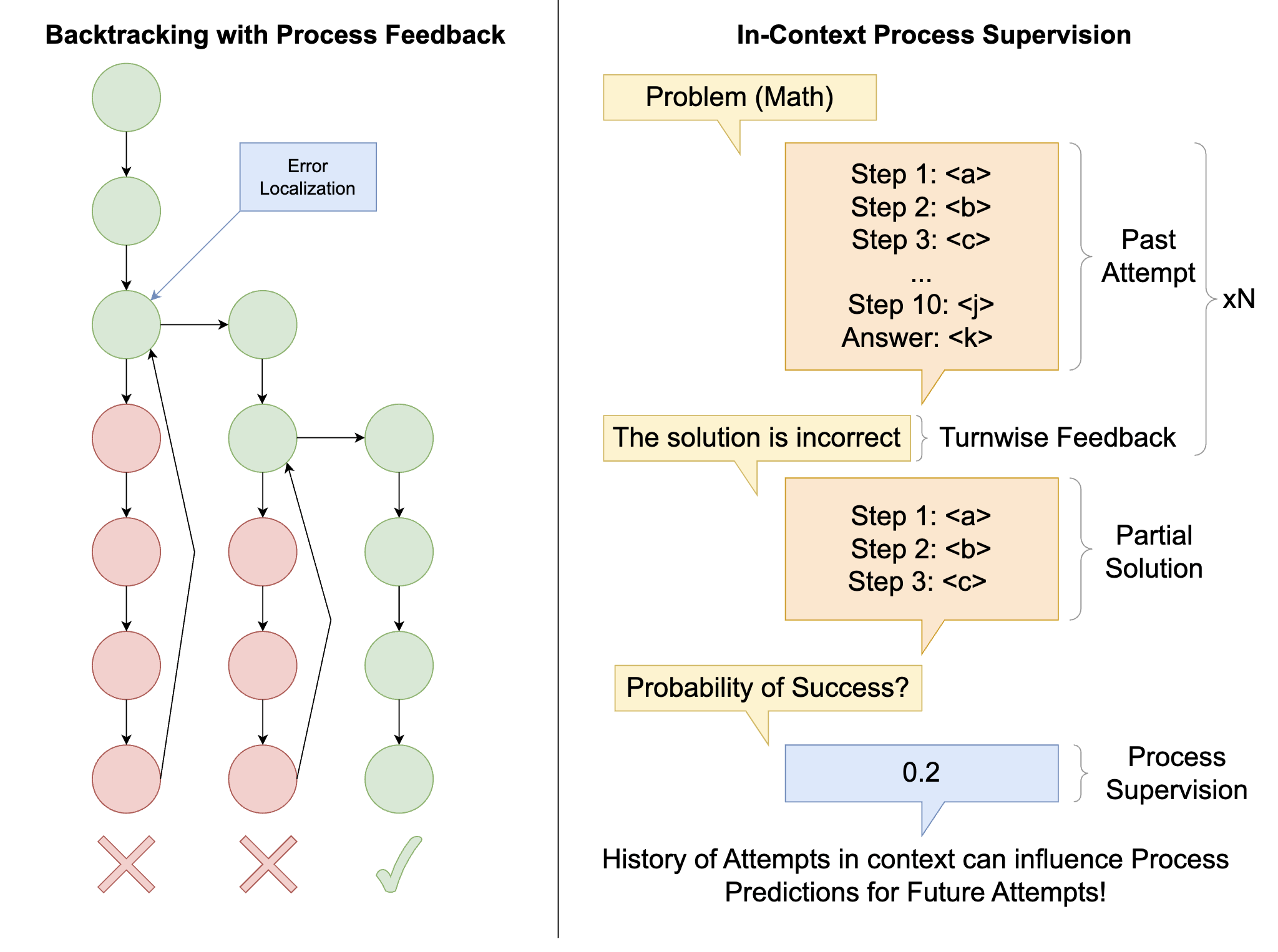
Improving Test-Time Search in LLMs with Backtracking Against In-Context Value Verifiers
This paper introduces a novel approach combining process verifiers with preemptive backtracking to efficiently identify and resample problematic steps, significantly reducing computation through focused revisions and in-context process supervision. 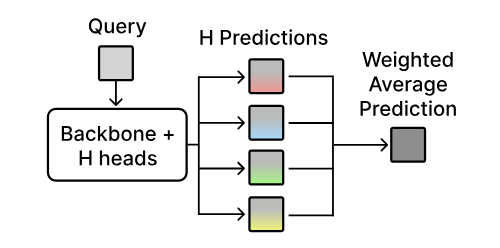
Test-Time Alignment via Hypothesis Reweighting
We introduce HyRe, a test-time adaptation framework that trains a single neural network with multiple prediction heads—each encoding a different behavior consistent with the training data—and dynamically reweights them using a small set of labeled examples from the target distribution. With only five preference pairs per distribution, HyRe scales to large pretrained models at roughly the cost of fine-tuning one model and outperforms prior state-of-the-art 2B-parameter reward models across 18 personalization and distribution-shift scenarios. 
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. 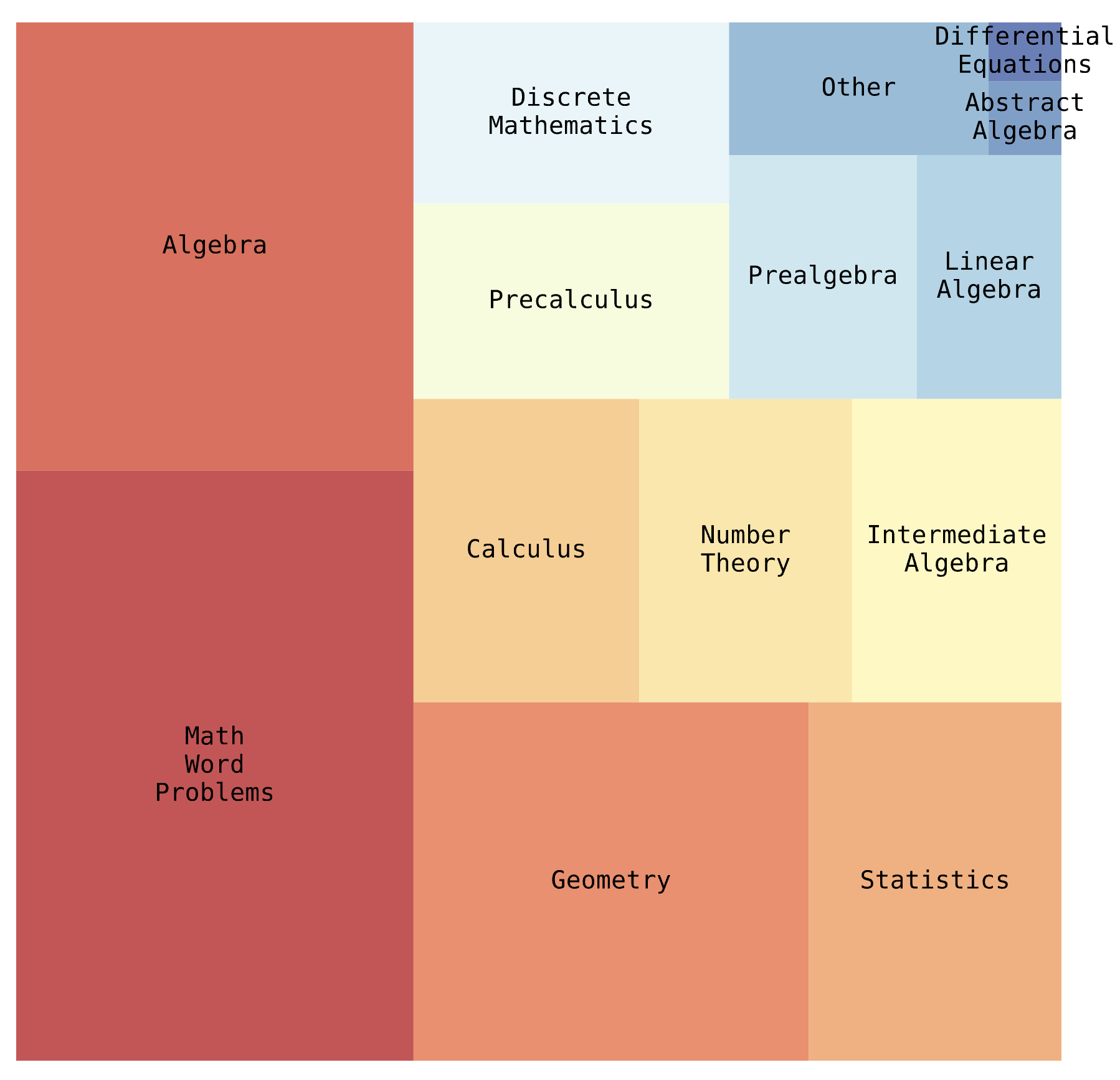
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
Big-Math is a dataset of over 250,000 high-quality, verifiable math questions created for reinforcement learning that bridges the gap between quality and quantity by rigorously filtering existing datasets and introducing 47,000 new reformulated questions, offering greater diversity and varying difficulty levels compared to commonly used alternatives like GSM8k and MATH. 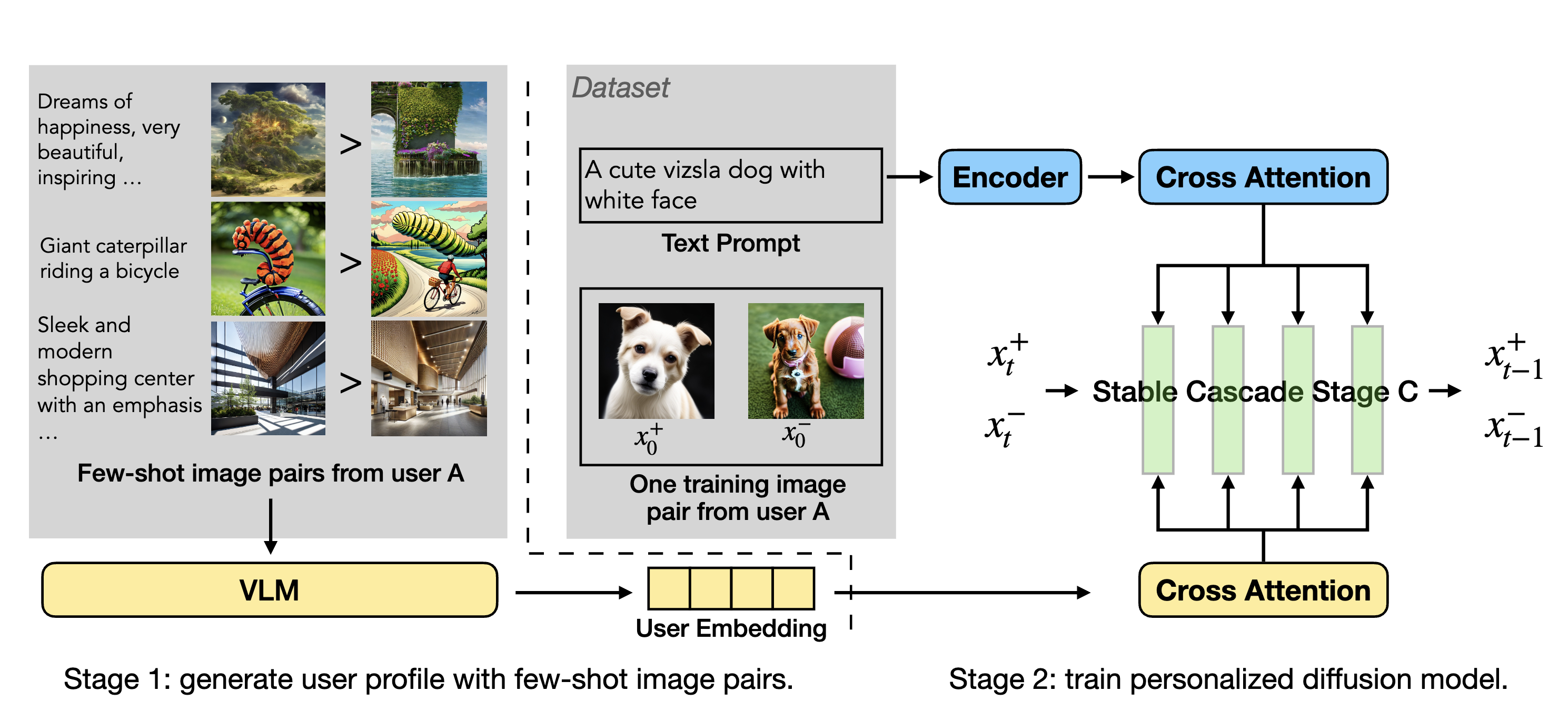
Personalized Preference Fine-tuning of Diffusion Models
PPD is a multi-reward optimization approach that personalizes text-to-image diffusion models by extracting user preference embeddings from a few examples and incorporating them via cross-attention during DPO fine-tuning, enabling effective generalization to unseen users with as few as four preference examples. 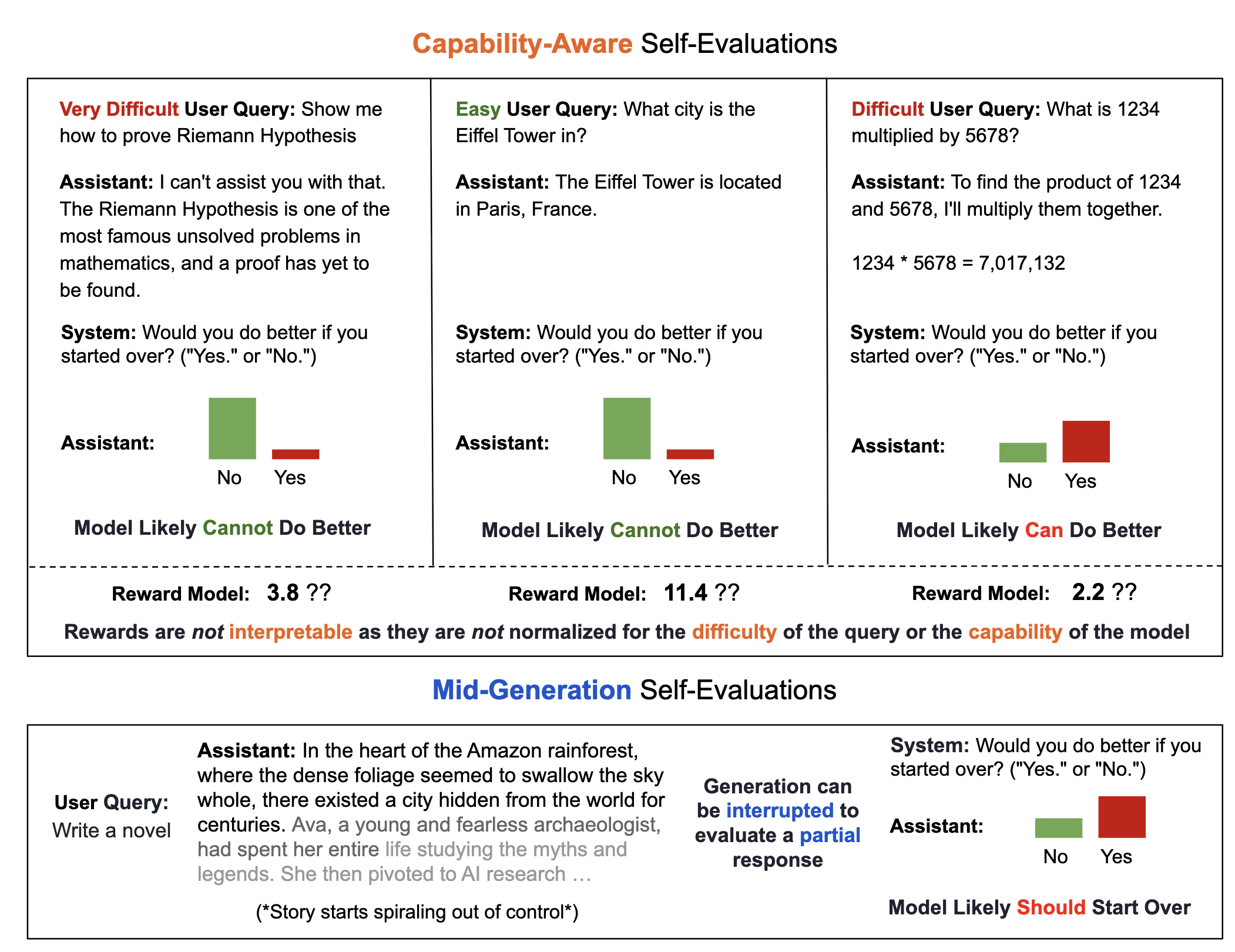
Adaptive inference-time compute: Large Language Models can predict if they can do better, even mid-generation
This paper proposes a generative self-evaluation scheme enabling large language models (LLMs) to internally predict mid-generation whether restarting would yield improved responses, significantly reducing computational costs by adaptively limiting sample generation. Experiments show this method achieves most of the performance gains of extensive multi-sample generation (e.g., increasing Llama 3.1 8B's win rate against GPT-4 from 21% to 34%) with dramatically fewer samples and minimal overhead. 
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
Learning from preferences is a common paradigm for fine-tuning language models. Yet, many algorithmic design decisions come into play. Our new work finds that approaches employing on-policy sampling or negative gradients outperform offline, maximum likelihood objectives. 
D5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning
Offline RL algorithms enable data-driven methods without the need for costly or dangerous real-world exploration, leveraging large pre-collected datasets. However, effective and challenging benchmarks that capture real-world task properties are necessary for evaluating progress, prompting the proposal of a new benchmark for offline RL based on realistic robotic simulations and diverse data sources to support both offline RL and online fine-tuning evaluation. 
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
VPTR is a framework that combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that are robust and generalizable. 
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
This is an opensource dataset comprised of a large collection of robot embodiments. We study how vision-language models trained on X-Embodiment Datasets can enable efficient adaptation to new robots, tasks, and environments. 
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. 
Offline RL With Realistic Datasets: Heteroskedasticity and Support Constraints
CQL (ReDS) is an offline RL method that modifies a typical distribution constraint into an approximate support-level constraint via re-weighting to enable efficient learning from heteroskedastic dataset compositions. 
Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning
A method that learns a conservative value function initialization that underestimates the value of the learned policy from offline data, while also being calibrated, in the sense that the learned Q-values are at a reasonable scale. This leads to effective online fine-tuning, enabling benefits of offline initializations in online fine-tuning 
Pre-Training for Robots: Offline RL Enables Learning from a Handful of Trials
PTR is a framework based on offline RL that attempts to effectively learn new tasks by combining pre-training on existing robotic datasets with rapid fine-tuning on a new task, with as few as 10 demonstrations. 
When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning?
Theoretical paper that characterize the properties of environments that allow offline RL methods to perform better than BC methods, even when only provided with expert data. Additionally, policies trained on sufficiently noisy suboptimal data outperform BC algorithms with expert data, especially on long-horizon problems. 
A Workflow for Offline Model-Free Robotic Reinforcement Learning
Our proposed workflow aims to detect overfitting and underfitting in model-free offline RL, and provides guidelines for addressing these issues via policy selection, regularization, and architecture design. 
A Mobile Application for Keyword Search in Real-World Scenes
System to help visually-impaired patients localize where words are present in a cluttered environment. This system utilizes OCR + Levenshtein Distance along with specialized audio cues and additional assistive features to enable efficient and intuitive search in crowded, diverse environments. |
TeachingGraduate Student Instructor, CS224r Spring 2025 Program Coordinator, Mentor, Deep Learning Portal 2024 
Undergraduate Student Instructor, CS285 Fall 2022 Undergraduate Student Instructor, CS188 Spring 2022 Undergraduate Student Instructor, CS285 Fall 2021 |